前回、Chart.jsのPie chartをReactで表示してみました。
React + react-chartjs-2 + Chart.js を使って、Pie chart を表示してみた - メモ的な思考的な
その続きとして、次はバックエンドからのレスポンスを React + Charts.js で描画したくなりました。
バックエンドは今までさわったことがないもので作ろうと考え、気になっていた Hono を使うことにしました。
では、HonoとReactをどう組み合わせればよいか調べたところ、以下の記事が参考になりました。
そこで、Hono + React + Chart.js + TanStack Router + TanStack Query な構成でアプリを作ってみたことから、そのときのメモを残します。
目次
- 環境
- Honoで Hello world する
- Hono + React でHTMLを表示する
- React + Chart.js で Pie chart を描画する
- TanStack Router によるルーティングを追加する
- WSL2向けのHMR を追加する
- HonoのJSONレスポンスの内容をChart.jsのdataとして使う
- Hono APIからのデータ取得に TanStack Query を使う
- ソースコード
環境
- Windows11 WSL2
- React 18.2.0
- Chart.js 4.4.2
- react-chartjs-2 5.2.0
- Hono 4.2.7
- 今回は Node.js テンプレートを使用する
- TanStack Router 1.30.1
- TanStack Query 5.32.0
Honoで Hello world する
初めて Hono を使うことから、まずは Hello world してみます。
各種ライブラリをインストールする
まず、公式ドキュメントの Quick Start に従い、Honoをセットアップします。
なお、今回はローカルだけで動かしどこにもデプロイしないことから、 nodejs テンプレートを選択しました。
$ npm create hono@latest create-hono version 0.7.0 ? Target directory my-app ? Which template do you want to use? nodejs ✔ Cloning the template ? Do you want to install project dependencies? yes ? Which package manager do you want to use? npm ✔ Installing project dependencies 🎉 Copied project files
Hello worldするには不要ですが、今後必要になるライブラリをインストールします。
まずはReactまわりをインストールします。
$ npm i react react-dom
続いて、開発で使う系です。型定義の他
- @vitejs/plugin-react-swc
- ReactアプリをSWCで変換
- @hono/vite-dev-server
- https://github.com/honojs/vite-plugins/tree/main/packages/dev-server
- テンプレートではNode.jsを指定しましたが、開発サーバとして vite-dev-server を使いたいため
をインストールします。
$ npm i -D @vitejs/plugin-react-swc @types/react @types/react-dom @hono/vite-dev-server
tsconfig.json を修正する
テンプレートの tsconfig.json に対し
- typesに
DOMとDOM.Iterableを追加 - jsxImportSource に
reactを指定
と修正します。
{ "compilerOptions": { "target": "ESNext", "module": "ESNext", "moduleResolution": "Bundler", "strict": true, "lib" : [ "ESNext", "DOM", "DOM.Iterable" ], "types": [ "node" ], "jsx": "react-jsx", "jsxImportSource": "react", } }
vite.config.ts を作成する
Node.jsテンプレートには vite.config.ts が含まれていなかったので新規作成します。
Hello world時点ではReactを使いませんが、一足先にReactの設定を追加しておきます。
import devServer from '@hono/vite-dev-server' import { defineConfig } from 'vite' import react from '@vitejs/plugin-react-swc' export default defineConfig(({ mode }) => { if (mode === 'client') { return { build: { rollupOptions: { input: './src/client.tsx', output: { entryFileNames: 'static/client.js' } } }, plugins: [react()] } } else { return { ssr: { external: ['react', 'react-dom'] }, plugins: [ devServer({ entry: 'src/index.ts' }) ] } } })
src/index.ts を修正する
vite-dev-server を使うため、 src/index.ts を修正します。
Node.jsで起動する部分はコメントアウトしておきます。
また、 export app も忘れずに行っておきます。
// import { serve } from '@hono/node-server' import { Hono } from 'hono' const app = new Hono() app.get('/', (c) => { return c.text('Hello Hono!') }) export default app // const port = 3000 // console.log(`Server is running on port ${port}`) // // serve({ // fetch: app.fetch, // port // })
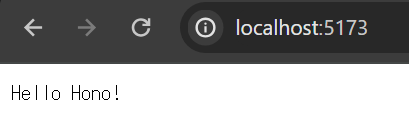
動作確認
npm run dev してブラウザでアクセスすると、以下が表示されました。
ここまでのコミット
Hono + React でHTMLを表示する
では、次にReactコンポーネントを表示してみます。
src/client.ts を src/client.tsx へリネームし、Reactコンポーネントを書く
テンプレートで生成された src/client.ts を `` へとリネームし、React コンポーネントを書きます。
import * as React from "react" import {createRoot} from "react-dom/client" const App = () => { return ( <h1>Hello world</h1> ) } createRoot(document.getElementById('root')!).render( <React.StrictMode> <App /> </React.StrictMode> )
src/index.tsx を修正する
JSONではなくHTMLを返すよう修正します。
import { Hono } from 'hono' import {renderToReadableStream, renderToString} from "react-dom/server" const app = new Hono() app.get('*', (c) => { return c.html( renderToString( <html> <head> <meta charSet="utf-8"/> <meta content="width=device-width, initial-scale=1" name="viewport"/> <title>React app</title> {import.meta.env.PROD ? ( <> <script type="module" src="/static/client.js"></script> </> ) : ( <> <script type="module" src="/src/client.tsx"></script> </> )} </head> <body> <div id="root"></div> </body> </html> ) ) }) export default app
TS2339 エラーへ対応するため、tsconfig.json を修正する
src/index.tsx を修正すると、以下のように
TS 2339: Property
envdoes not exist on typeImportMeta
というエラーが表示されます。

調べてみたところ、Vite.jsのドキュメントに記載がありました。
- Property 'env' does not exist on type 'ImportMeta' in 3.0.0 · Issue #9539 · vitejs/vite
- クライアントでの型 | 特徴 | Vite
- vue.js - Typescript Types for import.meta.env - Stack Overflow
今回は
tsconfig.json内のcompilerOptions.typesにvite/clientを追加
という方向で対応します。
// ... "types": [ "node", "vite/client" // 追加 ], // ...
vite.config.ts を修正する
src/client.tsx へリネームしたことから、 entry の定義を修正します。
plugins: [ devServer({ entry: 'src/index.tsx' // 修正後 }) ]
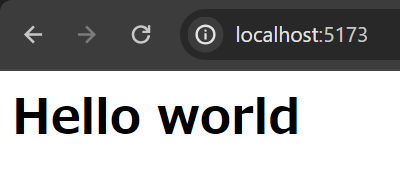
動作確認
ブラウザでアクセスすると、以下が表示されました。コンポーネントで定義した Hello world が表示されています。
ここまでのコミット
React + Chart.js で Pie chart を描画する
次は Chart.js で Pie chart を描画してみます。
Chart.js まわりをインストールする
Chart.js で Pie chart を描画するため、前回同様、以下をインストールします。
$ npm i chart.js react-chartjs-2
src/client.tsx を修正する
Pie chartを表示するよう修正します。
なお、まずは Pie chart が表示されるかだけ確認することから、 Pie chart のデータは React コンポーネントの中にハードコーディングしておきます。
また、Pie chart が画面いっぱい表示されるのを防ぐために、 <div style={{width: '300px'}}> としてサイズを指定しています。
import * as React from "react" import {createRoot} from "react-dom/client" import {ArcElement, Chart as ChartJS, Legend, Tooltip} from 'chart.js' import {Pie} from 'react-chartjs-2' const ChartComponent = () => { ChartJS.register(ArcElement, Tooltip, Legend) const data = { labels: ['奥州ロマン', 'シナノゴールド', 'ピンクレディ', 'ブラムリー'], datasets: [ { label: '購入数', data: [1, 5, 3, 2], backgroundColor: [ 'firebrick', 'gold', 'pink', 'mediumseagreen' ], borderColor: [ 'firebrick', 'gold', 'pink', 'mediumseagreen' ], borderWidth: 1 } ] } return ( <div style={{width: '300px'}}> <Pie data={data} /> </div> ) } const App = () => { return ( <> <h1>Hello world</h1> <ChartComponent/> </> ) } createRoot(document.getElementById('root')!).render( <React.StrictMode> <App /> </React.StrictMode> )
動作確認
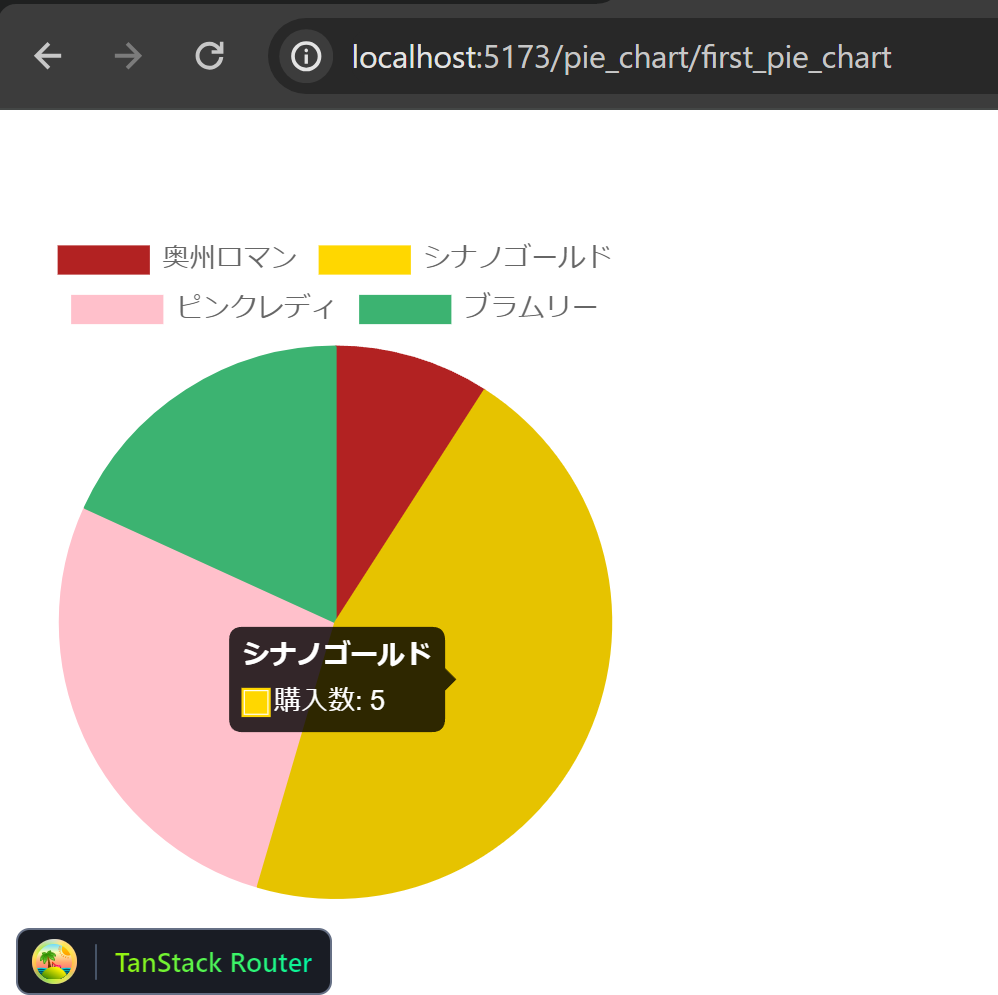
ブラウザでアクセスすると、Pie chart が表示されました。
ここまでのコミット
TanStack Router によるルーティングを追加する
本題とは異なるのですが、 Hono + React 構成とした場合にフロントエンドでのルーティングもできるかためしてみます。
ルーティングのライブラリとして、前回の記事同様 TanStack Router を使います。
TanStack Router
TanStack Router まわりをインストールする
必要なものをインストールします。
$ npm i @tanstack/react-router @tanstack/router-vite-plugin @tanstack/router-devtools
Reactのコンポーネントを修正する
TanStack Routerでルーティングするため、Reactのコンポーネント群を移動・修正します。
今回は以下の方針とします。
- Reactコンポーネントは
src/clientディレクトリの中に入れる - エントリポイントは
src/client/main.tsxファイルにする - 各ページのコンポーネントは
src/client/routesディレクトリの中に入れる
src/client/main.tsx を作成する
TanStack Routerのドキュメントに従い、エントリポイントとなるファイルを作成します。
import {createRoot} from "react-dom/client"; import * as React from "react"; import {createRouter, RouterProvider} from "@tanstack/react-router"; import {routeTree} from "./routeTree.gen" const router = createRouter({ routeTree }) declare module '@tanstack/react-router' { interface Register { router: typeof router } } createRoot(document.getElementById('root')!).render( <React.StrictMode> <RouterProvider router={router} /> </React.StrictMode> )
src/client/routes/__root.tsx ファイルを作成する
TanStack Routerで必要な src/client/routes/__root.tsx を作成します。
中身はほぼ空で、各ページのコンポーネントと TanStackRouterDevtools だけ置いておきます。
import {createRootRoute, Outlet} from "@tanstack/react-router"; import {TanStackRouterDevtools} from "@tanstack/router-devtools"; export const Route = createRootRoute({ component: () => ( <> <Outlet /> <TanStackRouterDevtools /> </> ) })
/ 向けの index.lazy.tsx を作成する
/ にアクセスした時表示されるコンポーネント index.lazy.tsx を作成します。
今回はメッセージと Pie chart のあるページのリンクだけ置いておきます。
import {createLazyRoute, Link} from "@tanstack/react-router"; const Component = () => { return ( <> <h1>Hello, TanStack Router</h1> <Link to="/chart">Chart</Link> </> ) } export const Route = createLazyRoute('/')({ component: Component })
なお、TanStack Routerの Link コンポーネントですが、上記の書き方だと
Element Link does't have required attribute search
というワーニングが出ます。
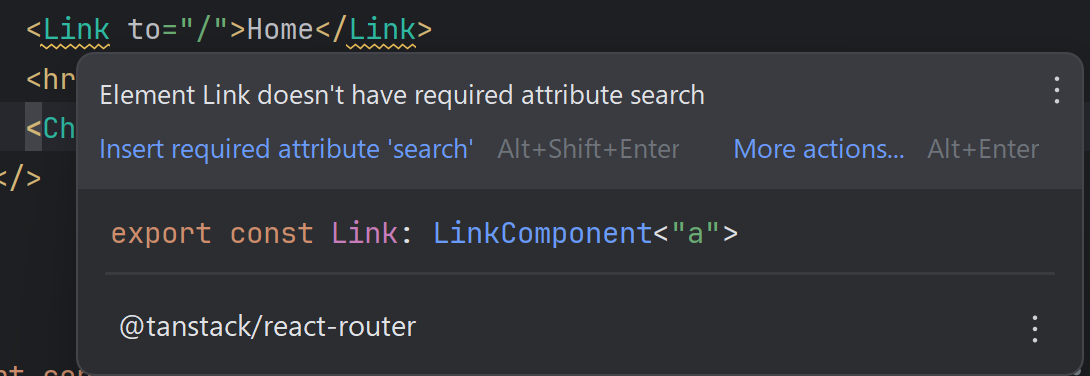
ただ、今回の実装には影響しないので、いったんこのままにしておきます。。
/chart 向けの chart.lazy.tsx を作成する
Pie chartを表示するコンポーネントを作成します。
なお、Pie chartのデータはまだフロントエンド側に置いたままにしておきます。
import {createLazyRoute, Link} from "@tanstack/react-router"; import * as React from "react" import {ArcElement, Chart as ChartJS, Legend, Tooltip} from 'chart.js' import {Pie} from 'react-chartjs-2' const ChartComponent = () => { ChartJS.register(ArcElement, Tooltip, Legend) const data = { labels: ['奥州ロマン', 'シナノゴールド', 'ピンクレディ', 'ブラムリー'], datasets: [ { label: '購入数', data: [1, 5, 3, 2], backgroundColor: [ 'firebrick', 'gold', 'pink', 'mediumseagreen' ], borderColor: [ 'firebrick', 'gold', 'pink', 'mediumseagreen' ], borderWidth: 1 } ] } return ( <div style={{width: '300px'}}> <Pie data={data} /> </div> ) } const Component = () => { return ( <> <h1>Hello, Chart</h1> <Link to="/">Home</Link> <hr /> <ChartComponent /> </> ) } export const Route = createLazyRoute('/chart')({ component: Component })
エントリポイントの移動に伴う修正をする
src/index.tsx を修正する
// 変更前 // <script type="module" src="/src/client.tsx"></script> // 変更後 <script type="module" src="/src/client/main.tsx"></script>
vite.config.ts を修正する
(今回は使いませんが) rollupOptions にエントリポイントとなるファイルの指定があるので差し替えます。
rollupOptions: { // 修正前 // input: './src/client.tsx', // 修正後 input: './src/client/main.tsx', // ... }
また、 plugins にも TanStackRouterVite を追加しておきます。
plugins: [ react(), TanStackRouterVite() // 追加 ]
tsr.config.json ファイルを追加する
TanStack Router のデフォルト設定とは異なり、今回は src/client の下にフロントエンドのファイルを置いています。
そのため、デフォルト設定のままだと TanStack Router が自動でルーティングファイルを生成するときに想定した動作になりません。
そこで、ルートディレクトリに tsr.config.json ファイルを追加し、今回のディレクトリ構成に合わせた設定にします。
Configuration | File-Based Routes | TanStack Router React Docs
{ "routesDirectory": "./src/client/routes", "generatedRouteTree": "./src/client/routeTree.gen.ts" }
Router CLI を使って src/client/routeTree.gen.ts を初期生成する
ここまでの設定をすれば routeTree.gen.ts をTanStack Routerが自動で生成してくれる想定でした。
ただ、今回はうまく生成できなかったことから、 Router CLI を使って初期生成します。
Router CLI | File-Based Routes | TanStack Router React Docs
まずは公式ドキュメントに従いパッケージを追加します。
$ npm install @tanstack/router-cli
続いて、Router CLI を使ってファイルを生成します。
$ tsr generate
動作確認
以上で準備ができたので、動作確認します。
まず / へブラウザでアクセスすると、以下が表示されました。
次に /chart へアクセスすると Pie chart が表示されました。
なお、各リンクも正しく動作しています。
ここまでのコミット
WSL2向けのHMR を追加する
今回WSL2上で開発しているせいか、ホットリロードがうまく動作しません。
そこで、以下の記事を参考に vite.config.ts へ設定を追加します。
Laravel Sailを使い、WSL2上にローカル環境を構築したが、Viteのホットリロードが動作しない
hmr: { host: 'localhost' }, watch: { usePolling: true }
設定追加後、コンポーネントファイルの修正を行うと、その内容が即座に反映されるようになりました。
ここまでのコミットは以下です。
https://github.com/thinkAmi-sandbox/react_chartjs_with_hono-example/pull/1/commits/57af2bae13baf86865fc2e77da48a467c84c78a3
HonoのJSONレスポンスの内容をChart.jsのdataとして使う
ようやく本題です。
src/index.tsx を修正し、HonoでJSONレスポンスを返す
今までフロントにハードコーディングしてあった Chart.js 向けのJSONを、Honoで返すよう修正します。
ちなみに、Honoではバックエンドとフロントエンドで型を共有する RPC という機能があるため、合わせて実装しておきます(今回は GET しか使わないので有益ではないかもしれませんが。。)。
RPC - Hono
import {Hono} from 'hono' import {renderToString} from "react-dom/server" const app = new Hono() const appleRoute = app.get('/api/apples', (c) => { return c.json({ labels: ['奥州ロマン', 'シナノゴールド', 'ピンクレディ', 'ブラムリー'], datasets: [ { label: '購入数', data: [1, 5, 3, 2], backgroundColor: [ 'firebrick', 'gold', 'pink', 'mediumseagreen' ], borderColor: [ 'firebrick', 'gold', 'pink', 'mediumseagreen' ], borderWidth: 1 } ] }) }) // フロントエンドと型を共有するため、export type しておく export type ApplesType = typeof appleRoute app.get('*', (c) => { return c.html( renderToString( <html> <head> <meta charSet="utf-8"/> <meta content="width=device-width, initial-scale=1" name="viewport"/> <title>React app</title> {import.meta.env.PROD ? ( <> <script type="module" src="/static/client.js"></script> </> ) : ( <> <script type="module" src="/src/client/main.tsx"></script> </> )} </head> <body> <div id="root"></div> </body> </html> ) ) }) export default app
src/client/routes/chart.lazy.tsx を修正し、HonoのレスポンスをChart.jsで描画する
今回は Hono の RPC 機能を使うため、 fetch関数を使うのではなく、Honoの hc 関数を使います。
https://hono.dev/guides/rpc#client
import {createLazyRoute, Link} from "@tanstack/react-router" import * as React from "react" import {useEffect, useState} from "react" import {ArcElement, Chart as ChartJS, ChartData, Legend, Tooltip} from 'chart.js' import {Pie} from 'react-chartjs-2' import {ApplesType} from "../../index" import {hc} from 'hono/client' type MyChart = ChartData<"pie", number[], unknown> // HonoのRPC機能を使う const client = hc<ApplesType>('http://localhost:5173') const ChartComponent = () => { ChartJS.register(ArcElement, Tooltip, Legend) const [data, setData] = useState<MyChart>() useEffect(() => { const fetchApples = async () => { const response = await client.api.apples.$get() console.log(response) if (response.ok) { const apples = await response.json() setData(apples) } } fetchApples() }, []) if (!data) return return ( <div style={{width: '300px'}}> <Pie data={data} /> </div> ) } const Component = () => { return ( <> <h1>Hello, Chart</h1> <Link to="/">Home</Link> <hr /> <ChartComponent /> </> ) } export const Route = createLazyRoute('/chart')({ component: Component })
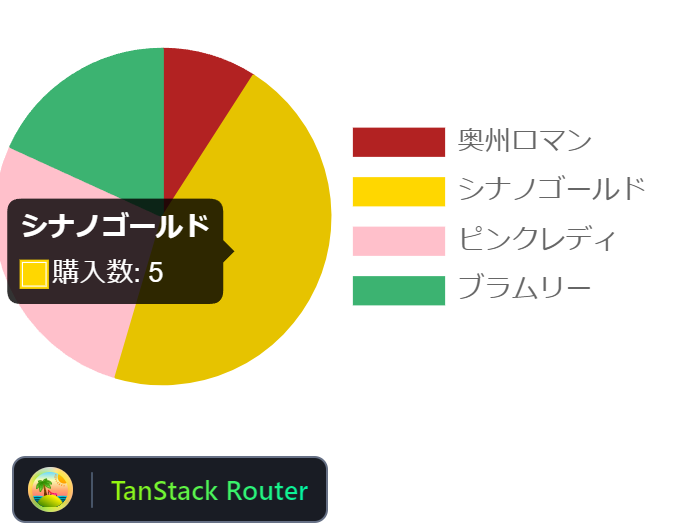
実装が終わったところで動作確認すると、Pie chartが同じように表示されました。
また、ブラウザのNetworkタブを見ても、バックエンドからデータが送信されていることが確認できました。
ここまでのコミット
Hono APIからのデータ取得に TanStack Query を使う
HonoのRPCドキュメントを見ていたところ
You can also use a React Hook library such as SWR.
との記載がありました。
そこで、TanStack Queryでもできるか気になったため、ためしてみることにします。
TanStack Query
TanStack Query をインストールする
$ npm i @tanstack/react-query
TanStack Query を使うよう修正する
src/client/main.tsx に TanStack Query用の設定を追加する
TanStack Queryを使えるよう
- queryClient の作成
<QueryClientProvider client={queryClient}>の追加
を行います。
import {createRoot} from "react-dom/client"; import * as React from "react"; import {createRouter, RouterProvider} from "@tanstack/react-router"; import {routeTree} from "./routeTree.gen" import {QueryClient, QueryClientProvider} from "@tanstack/react-query"; const queryClient = new QueryClient() const router = createRouter({ routeTree }) declare module '@tanstack/react-router' { interface Register { router: typeof router } } createRoot(document.getElementById('root')!).render( <QueryClientProvider client={queryClient}> <React.StrictMode> <RouterProvider router={router} /> </React.StrictMode> </QueryClientProvider> )
TanStack Query によるカスタムフックを追加する
Hono APIにリクエストを飛ばすところを、TanStack Queryを使ったカスタムフックにします。
なお、このカスタムフックの中で Hono の hc 関数を使っています。
import {hc} from 'hono/client' import {ApplesType} from "../../index"; import {useQuery} from "@tanstack/react-query"; const client = hc<ApplesType>('http://localhost:5173') const queryFn = async () => { const response = await client.api.apples.$get() if (response.ok) { return await response.json() } } export const useApplesApi = () => { return useQuery({ queryKey: ['ApiApples'], queryFn: queryFn }) }
src/client/routes/chart.lazy.tsx でカスタムフックを使うよう修正する
useEffect の中でHono APIを呼ぶところを、カスタムフックの利用へと修正します。
import {createLazyRoute, Link} from "@tanstack/react-router" import * as React from "react" import {ArcElement, Chart as ChartJS, Legend, Tooltip} from 'chart.js' import {Pie} from 'react-chartjs-2' import {useApplesApi} from "../hooks/useApplesApi" const ChartComponent = () => { ChartJS.register(ArcElement, Tooltip, Legend) const {data, isLoading} = useApplesApi() if (isLoading) return <div>Loading...</div> if (!data) return return ( <div style={{width: '300px'}}> <Pie data={data} /> </div> ) } const Component = () => { return ( <> <h1>Hello, Chart</h1> <Link to="/">Home</Link> <hr /> <ChartComponent /> </> ) } export const Route = createLazyRoute('/chart')({ component: Component })
実装が終わったので動作確認したところ、今までと変わらず Pie chart が表示されました。
ここまでのコミット
ソースコード
Githubに上げました。
https://github.com/thinkAmi-sandbox/react_chartjs_with_hono-example
今回のプルリクはこちら。
https://github.com/thinkAmi-sandbox/react_chartjs_with_hono-example/pull/1