最近、ドキュメントがあるツールやライブラリを使う場合、Google NotebookLM (以降、NotebookLM)にドキュメントを渡して読むことが多いです。英語であっても日本語でドキュメント内容に質問できたり、ドキュメントに書いてないことは「書いてない」と回答してくれるためです。
ただ、現在のNotebookLMではいくつかの制限があります。
Frequently Asked Questions - NotebookLM Help
- 一度読み込んだソースは更新してくれない
- ドキュメントを更新した場合、手動で読み込む必要がある
- 手動で読み込むのは、かなり手間
- NotebookLM Web ImporterというChrome拡張はあるものの、結局は該当のページを開く必要がある
- ドキュメントを更新した場合、手動で読み込む必要がある
- NotebookLMの検索機能を使えばNotebookLM自身が探しに行くこともできるが、ドキュメントを指定できない & 10個までしか対象にできない
- ソースの上限は50個まで
- ドキュメントによっては、ソースが50個よりも多い場合がある
何か良い方法がないか調べたところ、以下の記事のようにドキュメントをpdf化してNotebookLMに渡すことで、効率的にソースを更新できそうでした。一方、pdf化したときに、情報が欠落するのかどうかは気になりました。
NotebookLM便利活用情報 - laiso
Webサイトをpdf化するPythonスクリプトを書くことも考えましたが、せっかくなので、GAになったJetBrains の Junie の性能や使い方を確認する題材とするのが良さそうでした。
そこで、JetBrains Junie とともにIntelliJ Platform Plugin SDK のドキュメントをpdf化するPythonスクリプトを作り、そのpdfをGoogle NotebookLM のソースにしてみたことから、その時の様子をメモとして残します。
目次
- 環境
- 環境構築
- 事前調査
- JetBrains AI Assistant による設計
- JetBrains Junieによる設計と実装
- NotebookLMでの確認
- 余談:Repomix により1ファイル化したものをNotebookLMに渡す
- ソースコード
環境
- mac
- Python 3.12.10
- miseでインストール
- uv 0.6.17
- PyCharm 2025.1
- JetBrains AI Assistant plugin 251.23774.42.28.6
- JetBrains Junie plugin 251.72.165
環境構築
環境構築も含めてゼロからJunieに行ってもらうとクレジット消費が激しそうなので、環境構築は自分で行いました。
macのターミナルでmiseとuvを使って環境構築をします。
% mise use python@3.12.10 % uv init Initialized project `jetbrains-docs-py`
PyCharmの Python Interpreter を確認したところ、適切なバージョンで認識されていました。

事前調査
IntelliJ Platform Plugin SDK の robot.txt を確認
ドキュメントなのでおそらく問題ないとは思いつつ、 robots.txt を確認しました。
https://plugins.jetbrains.com/robots.txt
Disallow 指定されていなかったため、アクセスしても良さそうでした。
sitemap.xml の確認
robots.txtにはsitemap.xmlの記載があったので、pluginに関する sitemap を見に行きました。
robots.txt にあった https://plugins.jetbrains.com/sitemap_index.xml を経由した https://plugins.jetbrains.com/docs/intellij/sitemap.xml を見たところ、このxmlに記載してあるページをpdf化できれば良さそうでした。
JetBrains AI Assistant による設計
Junieだけで設計しても良かったのですが、AIモデルを指定できるAI Assistant だとどんな感じになるだろうと考え、まずは AI Assistant に設計を依頼しました。
https://plugins.jetbrains.com/docs/intellij/sitemap.xml に書かれているURLにあるWebページを一つのpdfとして取得したいです。Pythonを使って作成する場合、どのような設計・スクリプトにすればよいか検討してください。
次のような設計と必要なライブラリ、サンプルコードの回答がありました。

また、実行に必要なライブラリに関する情報もありました。
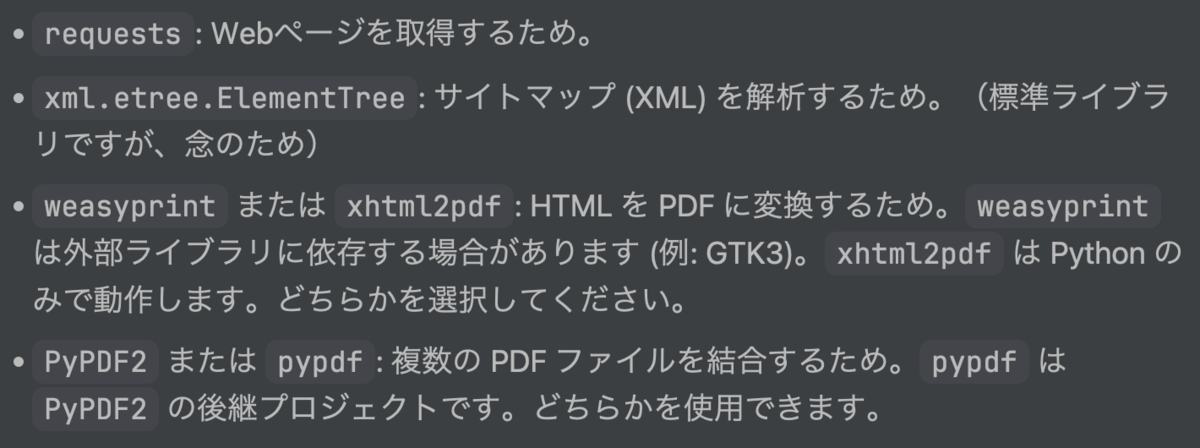
Pythonのみで動作しメンテナンスが続いているライブラリが良さそうと考えました。このライブラリのインストールもJunieに任せるとクレジットが...だったので、自分でインストールすることにしました。
% uv add requests beautifulsoup4 lxml xhtml2pdf pypdf
AI Assistant の回答でも実装できそうでしたが、次はJunieに設計と実装を任せてみることにしました。
JetBrains Junieによる設計と実装
今までJunieを使った設計と実装をしてなかったので、記録がてら細かめにメモしておきます。
なお、今回は .junie/guidelines.md を用意せずに作業を進めてもらうことにします。
Junie による設計
Junieではモードが Ask と Code の2つがありました。Clineの Plan と Act のようなものと考えています。
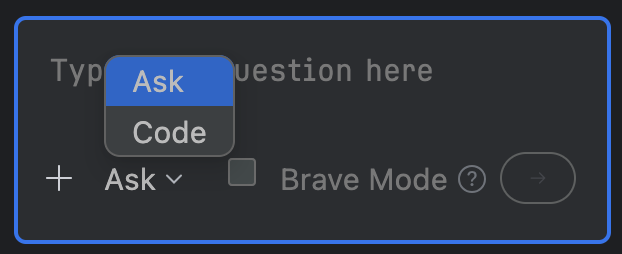
まずは設計から行ってもらうので、勝手に実装しないよう Ask へ切り替えて以下のプロンプトを入力しました。
https://plugins.jetbrains.com/docs/intellij/sitemap.xml に書かれているURLにあるWebページを一つのpdfとして取得したいです。Pythonを使って作成する場合、どのような設計・スクリプトにすればよいか検討してください
なお、必要と思われるライブラリはuvですでにインストール済です。pyproject.tomlを確認してください。
Junieが動き出すと、思考の過程が表示されます。プロンプトが日本語であっても、思考は英語のようです。
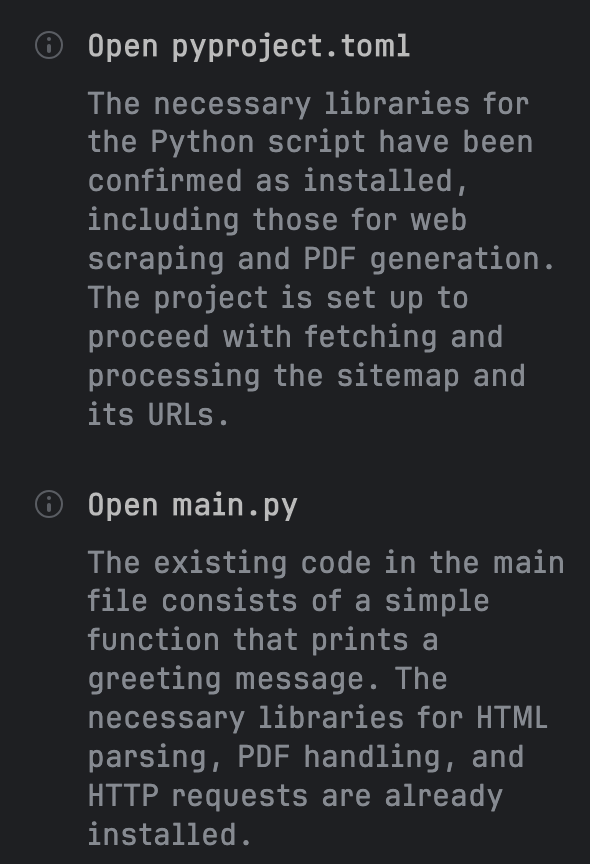
設計が終わると、 Response to Your Question が表示されます。Clineと違い、思考の続きにレスポンスが表示されず、 View in editor tab というリンクが表示されます。
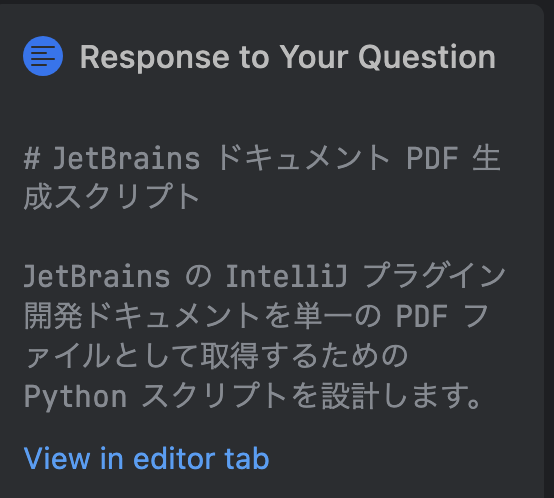
リンクをクリックすると、エディタの新しいタブが開き、設計結果が表示されます。設計といいつつ、実装コードも表示されています。
実装コードについては、「サーバに負荷をかけないようリクエスト間に遅延を設定」「エラー処理とロギング」なども含まれ、AI Assistant に比べるとやや実務寄りの実装のように感じました。

ちなみに、新しいエディタタブの内容は、左ペインの Scraches and Consoles の中に Scratches というのができ、その中にmarkdownファイルとして書かれているものを表示しているようです。これらのmarkdownファイルは git status しても出てこなかったことから、PyCharmが内部で管理しているものでしょうか。

Junieによる実装
初期実装
設計は良さそうだったので、Code モードへ切り替えて、Junieにコードを書いてもらうようにします。
その設計に従ってソースコードをmain.pyに書いてください
すると、Junieは動きだして編集を始めたようです。Clineと異なり、ファイル編集中の内容をdiff表示するのではなく、裏側で作業しているようです。作業が終わるとDoneの連絡が来ました。
ファイルのdiffを確認するために、ファイル名をホバーし、一番右の diff のアイコンをクリックします。
すると、JetBrains IDE上でのdiff確認と同じような、diffを確認できる画面が表示されました。
ここまででPythonスクリプトが完成しました。そこで python main.py で実行したところ、各ページのpdf化はうまくいったものの、pdfをマージするところでエラーになりました。
pypdf.errors.DeprecationError: PdfMerger is deprecated and was removed in pypdf 5.0.0. Use PdfWriter instead.
プログラムを修正したいところですが、pdf化は成功しているので、pdfをマージするだけのスクリプトが欲しくなりました。
pdfをマージするだけの機能で実装
そこで、Ask モードに切り替えて、pdfをマージするだけのPythonスクリプトを設計してもらいました。その際、やんわりと PdfMerger が使えないことも伝えました。
merge_pdfs 関数の中で PdfMergerが PdfWriter になったため、処理が失敗してしまいました。pdf化までは成功してそうなので、ここまでの実装をベースにmerge_pdfs関数だけを実行するPythonスクリプトを設計してください。
Junieはマージするだけの機能を持った実装コードを提案してきたものの、残念ながら PdfMerger を使うようになっていました。やんわりとでは伝わりません。。。

手抜きせずにエラーメッセージをきちんと渡して、再度設計してもらうことにしました。
pypdfのPdfMergerですが、バージョン5系で使おうとすると以下のエラーになります。PdfWriterを使うようにしてもらえませんか
pypdf.errors.DeprecationError: PdfMerger is deprecated and was removed in pypdf 5.0.0. Use PdfWriter instead.
すると、今度はPdfWriterを使うようになりました。また、単に置き換えるだけではなく、PdfWriterに合った実装へと変わりました。
設計はこれで良さそうだったので、再度 Code モードに切り替えて、実装を進めてもらいます。
ここまでの実装をベースにmerge_pdfs関数だけを実行するPythonスクリプト merge_docs.py を実装してください。pdfのマージは PdfWriterを使うバージョンにしてください。
Junieは実装を行い、終わったらDoneを返してきました。新しいファイルを作成した場合、そのファイル名をホバーすると Add to VCS のアイコンが追加されていました。
スクリプトを実行すると、すべてのpdfがマージされたpdfができました。
pdf化する機能とpdfを統合する機能を持ったPythonスクリプトを作成
手元には main.py と merge_docs.py の2つがあります。ただ、それぞれを使い分けるのは手間なので、両方の機能をもつPythonスクリプトを作ってもらうことにしました。
Ask モードへ切り替えて設計を依頼します。ただ、依頼文を書いている途中でtypoや加筆が必要なことに気づきました。そこで、修正するために 1to を入力したところでうっかりEnterだけを押してしまい、依頼が始まってしまいました (本来、改行するために Shift + Enter を押したかった)。
merge_docs.pyが正常に動いたので、最後はmain.pyとmerge_docs.pyを統合したスクリプト jb_docs.py を作りたいので、設計してください
スクリプトの条件としては、以下の1to
依頼をキャンセルすることができないので、設計が終わるのを待ちます。設計が終わったところで確認すると、意図を汲んでくれた上、必要そうなオプションも追加されていました。多少の変な文字やtypoは吸収するようです。

2つのPythonスクリプトにある機能がマージされてそうでした。そこで、 Code モードに切り替えて、実装を進めてもらいました。
Doneになったので確認すると、 jb_docs.py の作成の他に、 README.md の修正も行われていました。
Rollback機能を使えばJunieの行った修正を元に戻すこともできます。ただ、今回は気にするようなことではないので、修正はそのままにしました。
動作確認
できあがったスクリプトを python jb_docs.py にて実行し、動作を確認してみます。
ライブラリのワーニングが出たり、pngファイルに関するワーニングは出たものの、無事に終了しました。
XMLParsedAsHTMLWarning: It looks like you're using an HTML parser to parse an XML document.
Assuming this really is an XML document, what you're doing might work, but you should know that using an XML parser will be more reliable. To parse this document as XML, make sure you have the Python package 'lxml' installed, and pass the keyword argument `features="xml"` into the BeautifulSoup constructor.
If you want or need to use an HTML parser on this document, you can make this warning go away by filtering it. To do that, run this code before calling the BeautifulSoup constructor:
from bs4 import XMLParsedAsHTMLWarning
import warnings
warnings.filterwarnings("ignore", category=XMLParsedAsHTMLWarning)
soup = BeautifulSoup(response.content, 'lxml')
2025-05-01 08:36:12,943 - INFO - 385個のURLを抽出しました
2025-05-01 08:36:12,943 - INFO - ページを取得中: https://plugins.jetbrains.com/docs/intellij/components.html
2025-05-01 08:36:13,492 - INFO - PDFに変換しました: https://plugins.jetbrains.com/docs/intellij/components.html -> temp_pdfs/page_0.pdf
2025-05-01 08:36:14,497 - INFO - ページを取得中: https://plugins.jetbrains.com/docs/intellij/principles.html
2025-05-01 08:36:15,022 - INFO - PDFに変換しました: https://plugins.jetbrains.com/docs/intellij/principles.html -> temp_pdfs/page_1.pdf
2025-05-01 08:36:16,028 - INFO - ページを取得中: https://plugins.jetbrains.com/docs/intellij/ui-kit.html
2025-05-01 08:36:16,531 - WARNING - Could not get image data from src attribute: images/intuikit.png
'<img alt="Intuikit" height="424" src="images/intuikit.png" title="Intuikit" width="706"/>'
...
2025-05-01 08:49:44,111 - INFO - PDFを追加しました: temp_pdfs/page_384.pdf
2025-05-01 08:49:44,357 - INFO - PDFを結合しました: jetbrains_intellij_docs.pdf
2025-05-01 08:49:44,357 - INFO - すべてのドキュメントを結合しました: jetbrains_intellij_docs.pdf
ファイルを確認すると、1,000ページ超のpdfができていました。
中身を見ると、site_map.xml の掲載順なのでWeb上での分類とは異なる順でpdfができていたり、所々文字化けしていたりと、人間が見るのには不便なpdfになっていました。

ただ、NotebookLMが見る分には問題ないかもしれないと考え、pdfの細かな調整は行わないようにしました。
感想
今回 .junie/guidelines.md は整備しませんでしたが、これくらいのタスクであればプロンプトで十分対応できるとわかりました。どこまで対応できるかは今後も検証していきたいです。
一方、設計や実装速度については、Clineに比べるとまだまだ感がありました。今回は「Junieの作業中は別の作業をして過ごし、PyCharmからの通知で結果を確認する」みたいな使い方だったのでストレスを感じませんでしたが、Junieとペアプロするみたいな使い方は現状だと...という感じです。
Junieはリリースされたばかりということもあり、今後に期待しています。
NotebookLMでの確認
NotebookLMにJunieが作成したpdfを渡してみます。
まず、NotebookLMに渡せるpdfの仕様を確認しました。今回のpdfは1,000ページは超えているものの、図はないことから
- PDF upload via Drive is not yet supported. Please upload PDFs from your computer or as a web URL.
- Starting April 2025, NotebookLM has enhanced its ability to understand PDFs that have both texts and images.
あたりの影響はなさそうでした。
また、ファイルサイズも7MB弱だったため、
If the source length exceeds the allowed word limit (500,000 words per source) or over the file size allowed (200MB), or if your original PDF file is copy-protected, NotebookLM won't be able to import those sources.
の影響もなさそうでした。
ということで、NotebookLMに渡したところ、問題なくソースとして利用できました。
ではどこまで情報が劣化しているかを確認します。ソースとして
- ドキュメントの各URLを渡す
- ドキュメントのpdfを渡す
をそれぞれ指定した2つのNotebookLMを用意し、両方に「PSIとはなにか教えて下さい」という雑な質問をしてみます。
まず、ソースとして各URLを一つずつ渡した場合です。こちらはNotebookLMの回答は構造化されていて、読みやすい感じでした。また、内容も適切でした。

続いてpdfをソースとして渡した場合です。構造化の甘いところもありますが、書いてあることは各URL版と同じでした。

今回、そこまでの情報の劣化は感じられませんでした。そのため、ソースを手動で更新するという手間のことを考えると、pdf化して読み込ませる方法のほうが良さそうと感じました。
とはいえ、1件だけで判断するのは良くないことから、引き続き確認していこうと思います。
余談:Repomix により1ファイル化したものをNotebookLMに渡す
実は今回の取り組みを行う前に、「Repomix により1ファイル化したものをNotebookLMに渡す」ことも試していました。
JetBrainsの IntelliJ Platform Plugin SDK のドキュメントは、GitHubにて管理されているためです。
https://github.com/JetBrains/intellij-sdk-docs
そこで、Repomixを使って、次のように試してみました。
% mise use node@22.14.0 mise ~/project/docs_by_repomix/mise.toml tools: node@22.14.0 % npm install -g repomix % repomix --include "**/topics/**/*.md,**/reference_guide/**/*.md" --style markdown --output indellij-sdk-docs.md ./intellij-sdk-docs
しかし、GitHub上ではドキュメント間のリンクが正しい値になっていなかったこともあってか、Webページの各リンクを直接ソースとして渡す方法に比べるとかなり情報が劣化していました。
GitHub上のドキュメントをビルドできれば良さそうになる気がしたものの、このケースではRepomixによる単一ファイル化を採用するのは厳しそうでした。
ソースコード
今回 JetBrains Junie に作ってもらったソースコードはGitHubに置きました。なお、作成したpdfファイルは容量が大きかったため、gitignoreしてあります。
https://github.com/thinkAmi-sandbox/jetbrains_docs_py-example